-
一文讲透 2026半SPC中的Cpk.G到底是个啥?什么时候用CPK或者CPK.G??
质量行业流传最多的是“CPK是短期过程能力指数,而PPK是长期过程能力指数”。
那么,有好事者就问了:多短算是短期?多长算是长期?
有专家说:通常3个月算短期,半年算是长期。
好事者马上追问,那么29天算不算短期?28天、27天呢?3个月少一天算不算长期?疯掉了,到底哪个对,短期长期是什么意思?
其实熟悉我的朋友都知道,我们之前就强调过:CPK适用于稳定的过程(可预测未来),PPK适用于所有过程(只能描述当前)。关键在于数据是否“稳定”且“符合正态分布”,而不是单纯按照时间长短或数据点数目来决定。
我们来看看 AIAG-VDA SPC 黄皮书里提到的一个Cpk.G。它到底是个什么鬼?为什么在它的体系里 Cpk.G=Ppk.G?算它需要多少数据量?这篇文章一次性给你讲清楚。
一、那个神秘的后缀“.G”到底代表什么?
在ISO22514和3534系列标准中,引入了带.G后缀的指数。指数的这种命名方式,是用来表明记录数据时的边界条件以及当前的控制状态。
为了让你好理解,黄皮书里列举了两个典型场景:
- Pm.G/Pmk.G:表示该指数基于的数据,仅仅描述了生产设备(“机器”)的影响。在研究期间,其他的M(方法、人、材料、环境)都是保持恒定的。
- p.G/Cpk.G:这才是我们的“终极形态”。它表示一个考虑了所有过程影响因素的指数。而且,它有一个硬性前提:必须具备能力条件,也就是说,它必须被认为是一个受控过程。
简单来说,传统的CPK我们有时候稀里糊涂抓一把数据就算了,但Cpk.G要求你必须拍着胸脯保证:人机料法环我都考虑进去了,并且我的控制图显示现在过程稳得很!
二、Cpk.G的公式有什么玄机?为什么它更靠谱?
以前我们算传统的CPK,大家都在纠结组内标准差的到底怎么算。为了算一个σ,我们要算各种平方和,还要除以复杂的常量C4(d+1)甚至是Gamma函数。但ISO体系和AIAG-VDA的黄皮书给了另一种更贴近数据本质的解法——百分位数法。
根据ISO的计算方法,能力和性能指数使用的是下面这套基于过程实际散布的公式:

对于单侧能力指数(比如上限),公式是这样的:
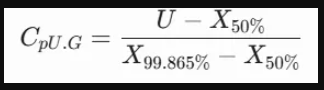
看出区别了吗?
它的分母不再是你硬套公式算出来的6σ,而是直接看数据实际分布的99.73%散布范围(即用99.865%的分位数减去0.135%的分位数)。它的均值位置也不是简单的算术平均,而是采用了中位数X50%。
这种算法的最大好处就是“不装”。它直接看你真实数据的分布边缘在哪里,特别是在应对非完美正态分布的现实工况时,百分位数法能够给出更真实的能力评估。
三、颠覆认知:为什么Cpk.G竟然等于Ppk.G?
这可能是很多质量人第一次听到这个结论,但从数学逻辑上讲,在百分位数法的框架下:
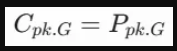
为什么?
因为不管是算Cpk.G还是Ppk.G,我们使用的都是同一组经验数据的实际百分位数(即所有数据混在一起排序后找位置)。
- 在传统的计算中,CPK用的是“组内标准差”(反映短期波动),而PPK用的是“整体标准差”(反映长期波动)。两者因为计算σ的方法不同,所以数值通常不同。
- 但在.G的百分位数法中,根本就没有组内、组间标准差的区别了。大家都是直接找那批数据的99.865%和0.135%位置的数值。
既然数值一样,那还分这两个名字干嘛?
区别完全在于你对这批数据的“控制状态”的断定:
- 如果你的过程是稳定且受控的(控制图没有异常点),这套基于百分位数算出来的结果,我们叫它Cpk.G,代表你的过程有真正的“能力”。
- 如果你的过程是不受控的(或者你根本没做控制图,只是收集了一堆历史数据),同一套公式算出来的结果,对不起,你只能叫它Ppk.G,它只能代表你这段时间的“性能表现”,不能用来预测未来。
其实,以前的Pmk和Cpk也是一样的公式,用哪个名称要看数据的前提。
四、样本量要求:想算Cpk.G,你需要多少数据?
知道了公式,那么问题来了:用百分位数法算Cpk.G,我的数据量要多少?25个够不够?
答案是:绝对不够!
我们来看看公式分母需要什么:0.135%的分位数和99.865%的分位数。
这意味着什么?如果你只有30个数据,你的第1个数据已经是3.3%的分位数了,你根本找不到0.135%在哪里,强行用软件去插值计算出来的数据也是极度失真的。
为了让极端百分位数的估计具有统计学意义,AIAG-VDA和ISO标准通常要求样本量大于等于125个。
- 如果是单值数据,你需要收集至少125个连续数据。
- 如果是有子组的数据,通常建议至少25组,每组5个(总计125个)。
数据量越少,百分位数的波动就越大,你算出来的Cpk.G就越像是在“抛硬币”。所以,如果你手头只有二三十个数据,老老实实去用传统的方法看CPK(前提是正态),别硬套Cpk.G。
五、总结:不要沦为数字游戏的奴隶
很多时候我们纠结指标,其实是陷入了“为了做报表而做数据”的怪圈。
不管是常规的CPK,还是今天讲的Cpk.G,它们都只是我们了解过程健康状况的体检表。有人觉得这些指标没用,认为它们只是“数字游戏”。
但真相是:指数本身没有错,错的是在数据性质不满足前提条件时,强行套用公式并盲目相信结果。
最后总结一下核心心法:
- 别再扯长期/短期:过程稳定+受控=看C系列;过程未知/不稳定=看P系列。
- Cpk.G的本质:抛弃算术平均和组内σ估算,直接用真实数据的百分位数(中位数,0.135%,99.865%)说话。
- Cpk.G=Ppk.G:算法一模一样,叫什么名字取决于你的过程是否在控。
- 样本量红线:没有125个数据打底,不要碰Cpk.G。
如果你觉得每次算这些都很头疼,或者团队还在用落后的手工Excel记录,其实现在有很多专业的WEB端SPC软件可以自动判异、自动计算。工欲善其事,必先利其器,把算数的时间省下来,去现场解决真正的质量问题吧!
本页面文章与公众号同步。

微信扫码关注